IP est un protocole permettant d’avoir une adresse logique pour les machines (contrairement aux adresses physiques d’Ethernet). Ces adresses sont fixées par l’administrateur du réseau (ce sont donc des adresses qui permettent d’organiser les adresses sur le réseau indépendament des machines). Une autre particularité des adresses Ethernet est qu’elles sont globales : une adresse IP publique est censée être unique dans le monde entier.
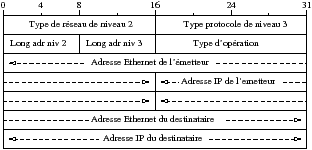
Les réseaux locaux sont des réseaux utilisant les adresses physiques des cartes. Par contre, si on ne connaît que l’adresse IP d’une machine il faut pouvoir retrouver son adresse MAC. Le mécanisme de résolution d’adresse proposé ici est le protocole ARP (Address Resolution Protocol) qui permet en deux échanges de trames de retrouver l’adresse MAC d’une machine à partir de son adresse IP.
Le protocole ARP est bien un protocole de niveau 3 car il permet au niveau réseau de savoir avec qui il veut communiquer sur le lien Ethernet. ARP est en fait indépendant d’Ethernet et fonctionne avec n’importe quel type de réseau de niveau 2. Après la résolution ARP, la couche de niveau 3 ne connaît que la taille des identifiants de niveau 2 et des valeurs numériques pour joindre les machines distantes. De cette façon IP peut fonctionner sur plusieurs types de protocoles de niveau 2 sans changer le principe de base de la résolution d’adresse ARP. Les requêtes ARP sont véhiculées dans des trames de niveau 2.
Une requête/réponse ARP est véhiculée par une trame Ethernet (sur
Ethernet donc) de type 0x0806. La machine émettrice envoie une requête
en broadcast (FF:FF:FF:FF:FF:FF) afin de contacter toutes les
machines du réseau local au niveau Ethernet. La machine qui reconnaît
son adresse IP peut renvoyer une réponse ARP en utilisant l’adresse
Ethernet inscrite dans la requête comme adresse de destination. Voici
un exemple de requête/réponse entre une machine d’adresse IP
129.104.254.6 cherchant à contacter la machine 129.104.254.5.
| Requête ARP | Réponse ARP |
|
|
Certains systèmes d’exploitation apprennent les adresses Ethernet des
autres machines en écoutant les requêtes ARP qui passent sur le
réseau.
Les traductions IP/ARP sont conservées dans une machine de façon
temporaire dans une table ARP. Vous pouvez voir le contenu de la table
de la machine sur laquelle vous êtes en tapant la commande (sous Unix)
arp -a.
0.8@percent
Une liste des protocoles supportés par IP est disponible sur les
machines Unix dans le fichier
/etc/protocols. Dans la suite
du cours nous ne nous interesserons qu’aux protocole ICMP (numéro 1),
UDP (numéro 17) et TCP (numéro 6)
Les adresses IP sont des nombres sur 32 bits dont la représentation usuelle est un groupe de 4 entiers sur 8 bits séparés par des points. Ainsi l’adresse 2262191317 (en décimal) correspond à l’adresse 134.214.76.213 dans la notation usuelle. Les adresses IP sont des adresses logiques qui sont fixées par configuration logicielle de la machine. Une machine a au moins autant d’adresses IP que d’interfaces (cartes) réseaux. Elle peut éventuellement en avoir plus.
Les adresses sur Internet sont gérées par l’organisme IANA. C’est l’organisme chargé de répartir les adresses IP dans le monde. Une première liste pour voir à qui appartiennent les tranches d’adresses est disponibles ici. La gestion est ensuite faite par des organismes régionaux (voir Ripe NCC).
La configuration d’une machine pour avoir une connexion IP se résume donc, pour l’instant aux paramètres suivants:
Le réseau local auquel est relié la machine est calculé en effectuant
un et logique entre l’adress IP de la machine et son masque de réseau.
Pour savoir si une machine destination est dans le même réseau il faut
faire la même opération avec l’adresse que l’on souhaite joindre et
son propre masque de réseau. Si le résultat est le même alors les deux
machines sont dans le même réseau local et la communication peut
s’effectuer via le réseau local. Dans le cas contraire la machine
source doit envoyer le datagramme au routeur de sortie (dont elle
connait l’adresse IP par configuration et qu’elle peut joindre en
utilisant le LAN). Le routeur se chargera de trouver le prochain saut
et ainsi d’acheminer le datagramme un peu plus loin dans le réseau
jusqu’à destinaition. Le nombre maximum de sauts autorisés (passage de
routeurs) est fixé au départ par la valeur du champs TTL. Si le TTL
arrive à 0 pendant le transport, alors le paquet est détruit et on
reçoit en retour un message ICMP de type 11 et de code 0.
0.8@percent
0.8@percent
La fragmentation fait intervenir les champs ID, Flags et Offset de l’entête pour remettre dans l’ordre les morceaux d’un paquet IP fragmenté au cours du routage dans le réseau.
Les routeurs intermédiaires peuvent fragmenter un paquet mais ne font pas la défragmentation. C’est à la machine destinatrice d’attendre et de remettre les fragments dans l’ordre. La machine utilise le champs TTL pour mesurer le temps maximum d’attente une fois qu’elle commence à réassembler un datagramme. Si ce TTL passe à 0 alors le datagramme est jeté car les morceaux n’ont pas été reçus à temps.
Le bit DF (don’t fragment) indique que l’on ne souhaite pas qu’un paquet puisse être fragmenté. Si le cas se présente le datagramme est jeté et un message ICMP est renvoyé à la source (type 3, code 4). Ce bit DF permet de faire de la découverte de MTU sur le chemin. Cette "MTU de chemin" est donc le plus gros datagramme que l’on puisse envoyer de bout en bout sans qu’il soit fragmenté (on a donc la MTU la plus petite de tous les réseaux traversés).
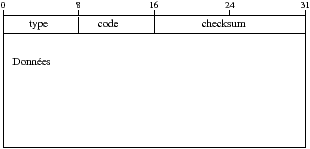
ICMP (Internet Control Message Protocol) est utilisé pour avoir des retours d’information sur l’état du réseau et des machines.
Les données, quand il y en a, dépendent du type de paquet ICMP. Si le paquet ICMP est un signalement d’erreurs alors le contenu des données est pris dans les 8 premiers octets des données du datagramme ayant généré l’erreur.
type 0 code=0 echo reply (requête) type 3 destination unreachable (messages d’erreurs) code 0 network unreachable code 1 host unreachable code 2 protocol unreachable code 3 port unreachable code 4 fragmentation needed but don’t-fragment bit set code 5 source route failed code 6 destination network unknown code 7 destination host unknown code 8 source host isolated (obsolete) code 9 destination network administratively prohibited code 10 destination host administratively prohibited code 11 network unreachable for TOS code 12 host unreachable for TOS code 13 communication administratively prohibited by filtering code 14 host precedence violation code 15 precedence cutoff in effect type 4 code=0 source quench (contrôle de flux) (messages d’erreurs) type 5 redirect (messages d’erreurs) code 0 redirect for network code 1 redirect for host code 2 redirect for type-of-service and network code 3 redirect for type-of-service and host type 8 code=0 echo request (ping) (requête) type 9 code=0 router advertisement (requête) type 10 code=0 router solicitation (requête) type 11 TTL (messages d’erreurs) code 0 TTL = 0 during transit code 1 TTL = 0 during reassembly type 12 parameter problem (messages d’erreurs) code 0 IP header bad code 1 required option missing type 13 code=0 timestamp request type 14 code=0 timestamp reply type 17 code=0 address mask request type 18 code=0 address mask reply
Tableau 4.1: Table des types et codes ICMP
Le champs ToS permet de donner une information sur la nature des données contenues dans le datagramme IP. Cette information peut être utilisée pour améliorer et diriger le routage. Il faut que les routeurs soient configurés pour en tenir compte. En pratique très peu de routeurs acceptent de prendre en compte le champs ce qui le rend inutile en pratique.
IP permet de communiquer avec une machine. Pour atteindre un service (application) il faut donc plus de précision dans l’adresse logique du destinataire du datagramme.
Les protocoles de transport UDP et TCP font l’interface entre le réseau (comment atteindre une machine) et les applications (comment atteindre un programme précis qui tourne dans une machine).
De la même manière que pour les adresses IP (il faut connaître une adresse IP à l’avance pour communiquer avec une machine), il faut connaître le port (numéro d’accès au service ou programme) pour accéder à un service particulier sur un serveur. Il existe pour cela une liste de référence connue sous le nom de "well known ports" qui est la même pour toutes les machines. Il s’agit ici d’établir une communication de bout en bout. Les deux protocoles utilisés sur l’Internet sont UDP et TCP.
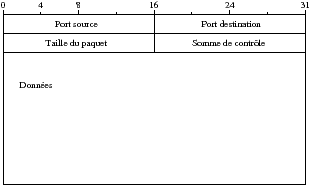
UDP est un protocole en mode datagramme et propose seulement le service de multiplexage applicatif par rapport à IP. UDP ne propose pas de service supplémentaire et on reste donc dans un mode non connecté avec des problèmes potentiels de perte de paquets dans le réseau (ce ne sera pas le cas de TCP).
UDP reste néanmoins un protocole rapide qui est très efficace et est utilisé par de nombreuses applications dont le service de nommage DNS (port 53)
UDP utilise IP comme support, il est donc soumis aux mêmes contraintes
Les données sont envoyées dès que l’application effectue une écriture. Chaque écriture de l’application génère un datagramme UDP. Les lectures des datagrammes depuis l’application se font sur des datagrammes complets.
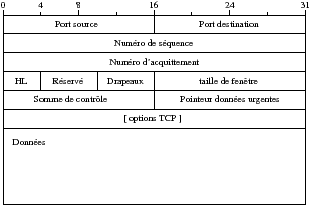
TCP permet d’avoir une connexion entre programmes ayant des propriétés bien plus complexes que les datagrammes UDP. TCP propose, par l’intermédiaire d’acquittements, d’avoir un contrôle de perte de paquet avec délivrement des données à l’application dans l’ordre d’envoi ainsi qu’un contrôle de congestion du réseau.
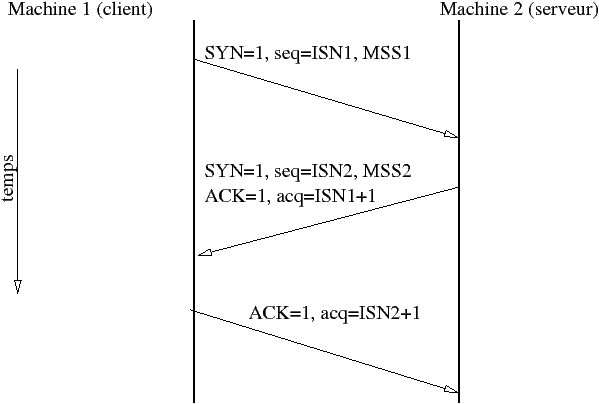
Les numéros de séquences et d’acquittements identifient le nombre d’octets transmis sur la connexion. Le compteur ne commence pas de zéro mais du nombre annoncé lors de la synchronisation d’ouverture de connexion (ISN: Initial Sequence Number).
Une communication TCP est identifiée par le quadruplet (adresse IP source, port source, adresse IP destination, port destination ).
L’option la plus courante dans TCP est l’annonce de la taille maximum de segment (MSS : Maximum Segment Size). Cette option est présente dans les segments ayant le bit SYN positionné pour indiqué quelle est la quantité maximale de données que veut recevoir l’émetteur. Lorsque la connexion est locale le MSS est fixé à la MTU du protocole de niveau 2 moins la taille des entêtes IP et TCP : pour un réseau ethernet le MSS sera fixé à 1460 dans la plupart des cas (cela peut dépendre des systèmes d’exploitation) sinon, pour une connexion distante, le MSS est fixé à 536 (la plus petite MTU sur Internet est fixée à 576 octets).
Les acquittements ne sont pas envoyés dès que l’on reçoit des données. Une temporisation de 500ms (au maximum) est mise en place pour augmenter la probabilité d’avoir des données à transmettre en même temps que l’acquittement et ainsi augmenter le débit utile du réseau.
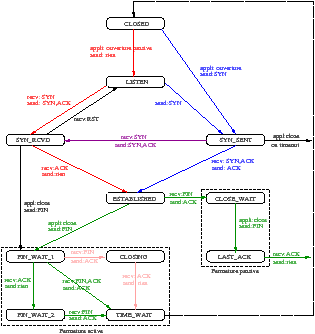
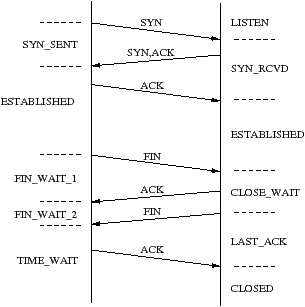
Le mécanisme d’ouverture de connexion TCP est prévu pour fonctionner dans le cas où les deux machines font une ouverture simultanée (cas très rare). Dans ce cas, une seule connexion TCP bidirectionnelle résulte de cette double ouverture.
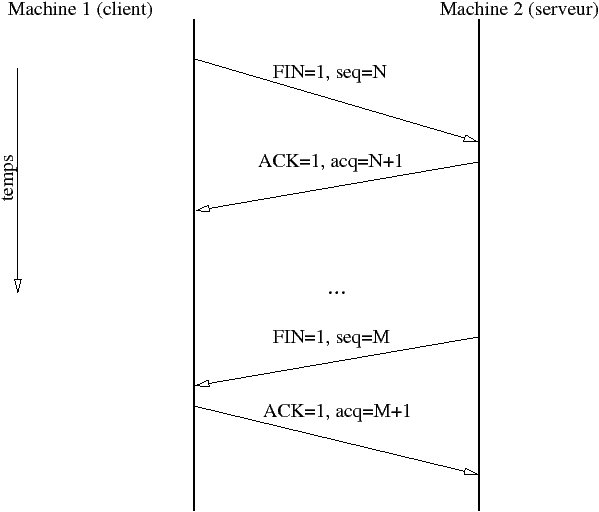
L’état TIME_WAIT est appelé état d’attente 2MSL. Un MSL est la durée de vie maximum d’un segment, cette valeur est comprise entre 30s et 2 min. C’est la durée maximale pendant laquelle un segment peut exister sur le réseau avant d’être rejeté.
Dans le cas d’une fermeture simltanée, la partie gauche et la partie droite passent par les états FIN_WAIT_1, CLOSING et TIME_WAIT au lieu de passer par les états mentionnés sur la figure précédente.
TCP propose des mécanismes pour désynchroniser les envois de segment des acquittements. Chaque machine annonce la quantité de mémoire disponible dans son buffer de réception (champs window dans l’entête TCP). L’émetteur sait alors quelle quantité de données il peut espérer envoyer sans saturer le destinataire. La taille de cette fenêtre peut varier de 8Ko à 16Ko (ou plus) selon les systèmes.
Une application qui aurait indiqué une fenêtre vide dans son dernier acquittement doit réémettre un segment avec le même numéro d’acquittement que le précédent pour réanoncer sa nouvelle taille de fenêtre.
L’envoi des segments ainsi que l’envoi des acquittements peut être différé par rapport aux données envoyées et lues de l’application (algorithmes de Clark et Nagle vus en TD)
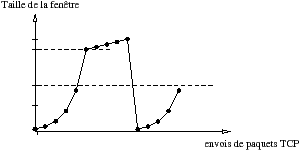
Le contrôle de congestion sert à adapter le débit de TCP par rapport aux pertes de paquets pouvant arriver dans le réseau. L’adaptation du débit dans TCP est appelé slow start.
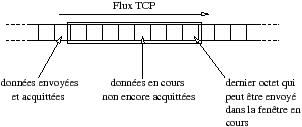
La fenêtre de réception permet à l’émetteur d’envoyer rapidement plusieurs segments TCP sans attendre d’acquittement entre l’envoi des segments. Ce mécanisme fonctionne très bien sur un même LAN mais peut poser des problème en cas de congestion du réseau.
TCP possède une fenêtre de gestion de la congestion appelée congestion window (cwnd). Cette fenêtre est locale à l’émetteur et sa valeur n’est pas inscrite dans l’entête de segment. Alors que la fenêtre annoncée dans les entêtes TCP conditionne la quantité de données traitées côté récepteur, la fenêtre de congestion conditionne la quantité de données qui peut être envoyée côté émetteur.
L’émetteur peut émettre à hauteur du minimum entre la taille de la fenêtre annoncée et la taille de la fenêtre de congestion.
L’émetteur commence à émettre un segment et attend l’acquittement. Une fois l’acquittement reçu, l’émetteur peut alors émettre deux segments et attendre les acquittements. La taille de la fenêtre de congestion est agrandie de façon exponentielle jusqu’à trouver la limite de congestion du réseau. Une fois cette limite atteinte, des segments commencent à se perdre et l’émetteur retombe alors à une fenêtre de congestion à 1. Il recommence le "slow start" exponentiel jusqu’au précédent point de rupture. Une fois le point de rupture atteint l’augmentation devient linéaire jusqu’au prochain seuil de rupture (et ainsi de suite).